La préhistoire d’Ethereum
Protocole Ethereum

Cet article écrit par Vitalik Buterin revient sur la genèse d’Ethereum et les atermoiements de la petite équipe d’origine autour de certains concepts qui constituent aujourd’hui la base du protocole. Traduction en français par Simon Polrot avec relecture et (nombreuses) corrections par Jean Zundel, Nathan Sexer, Johan Massin et Vincent le Gallic.
Même si les idées derrière le protocole Ethereum n’ont pas beaucoup changé pendant les trois dernières années, Ethereum n’a pas émergé d’un seul coup sous sa forme actuelle. Avant que la blockchain ne soit lancée, le protocole a subi un certain nombre d’évolutions et de changements de conception. L’objectif de cet article est de revenir sur la période entre les débuts et le lancement. Le travail incessant qui a été réalisé sur les implémentations du protocole telles que Geth, cppethereum, pyethereum et EthereumJ, ainsi que l’historique des applications et entreprises de l’écosystème sont délibérément hors du champ de cet article.
Casper et la recherche sur le sharding sont également en dehors du champ de cet article. Il est possible d’écrire de nombreux articles sur les idées diverses que Vlad, Gavin, moi-même et bien d’autres ont discutées et abandonnées, y compris la « proof of proof of work », les chaînes hub-and-spoke (en étoile), les « hypercubes », les shadow chains (qui peuvent être considérées comme des précurseurs de Plasma), les chain fibers, et plusieurs itérations de Casper, ainsi que les réflexions en constante évolution de Vlad sur les motivations des acteurs dans les protocoles de consensus et leurs propriétés, mais le tout constitue une histoire bien trop complexe pour l’explorer en un seul article et sera laissé de côté pour l’instant.
Commençons donc par la toute première version de ce qui deviendra Ethereum, à un moment où ce n’était même pas appelé Ethereum. En octobre 2013, pendant que je visitais Israël, j’ai passé beaucoup de temps avec l’équipe Mastercoin. Je leur ai même suggéré de nouvelles fonctionnalités. Après avoir réfléchi un moment à ce qu’ils étaient en train de faire, j’ai envoyé une proposition à l’équipe pour rendre leur protocole plus généraliste, afin qu’il puisse supporter plus de types de contrats sans ajouter un trop grand nombre de fonctionnalités complexes.
https://web.archive.org/web/20150627031414/http://vbuterin.com/ultimatescripting.html
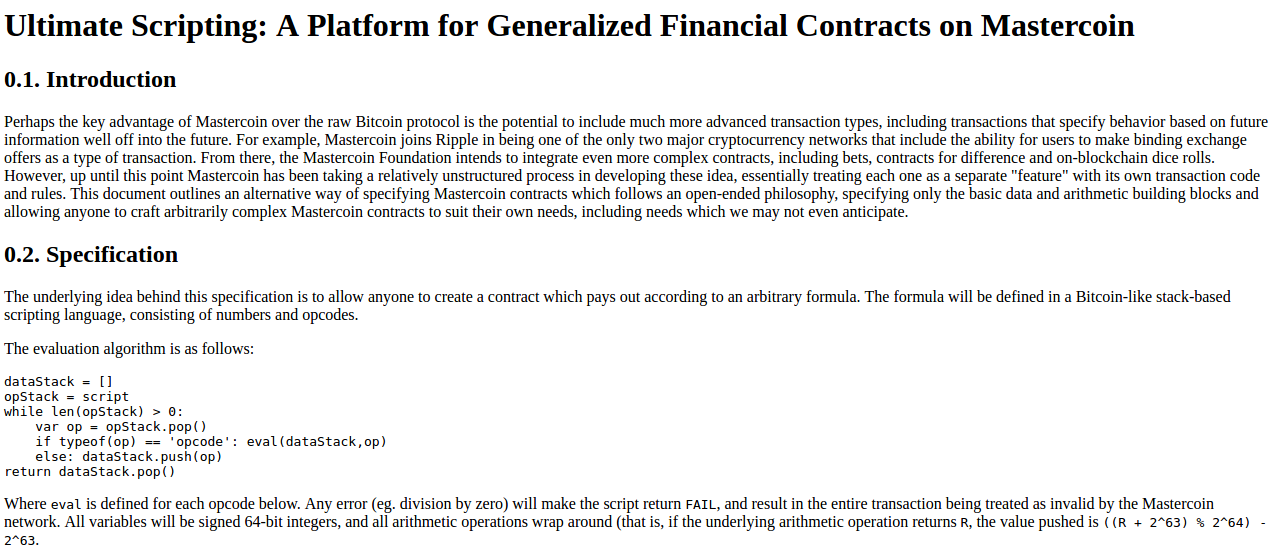
Notez qu’il s’agit d’une proposition très éloignée de la plus tardive et plus large vision d’Ethereum : elle se concentrait spécifiquement sur le domaine dans lequel Mastercoin tentait déjà de se spécialiser, c’est à dire des contrats bipartites où la partie A et la partie B mettent tous deux en consignation leur argent et reçoivent ensuite une somme dépendamment d’une formule spécifiée dans le contrat (par exemple un pari dans lequel « si X arrive alors donne tout l’argent à A, sinon donne tout l’argent a B »). Le langage de programmation n’était pas « Turing-complete ».
Les contributeurs de Mastercoin, bien qu’impressionnés par la proposition, n’étaient pas prêts à abandonner tout leur travail pour aller dans cette direction, alors que j’étais de plus en plus convaincu que c’était le choix le plus intéressant. Et voici comment est née la version 2, vers décembre de la même année :
https://web.archive.org/web/20131219030753/http://vitalik.ca/ethereum.html

Ici on peut voir les résultats d’une restructuration du concept qui résulte largement d’une longue marche à travers San Francisco faite en novembre, lorsque j’ai réalisé que les smart-contracts pouvaient être complètement généralisés. Au lieu de créer un langage de script simple permettant de décrire les termes d’une relation entre deux parties, les contrats seraient eux-mêmes des comptes à part entière sur la blockchain, qui auraient la capacité de détenir, d’envoyer et de recevoir des actifs, et même de gérer un stockage permanent de données (à cette époque, le stockage permanent était appelé « mémoire » (memory) et la seule « mémoire » temporaire résidait dans les 256 registres). Le langage utilisé a aussi changé d’une machine à pile à une machine à registres, à mon initiative. J’avais peu de raisons objectives pour justifier ce choix, sinon que cela semblait plus sophistiqué.
Notons également la présence d’un mécanisme de fees, de frais de transactions intégré au système :

L’ether était alors littéralement le gas d’aujourd’hui ; après chaque étape de calcul le solde du contrat qu’une transaction appelait diminuait un peu, et si le contrat n’avait plus de fonds l’exécution s’arrêtait. Notez que ce mécanisme du « receveur payeur » signifiait que le contrat lui-même devait s’assurer que les vendeurs payaient les frais au contrat et s’arrêter automatiquement si les frais n’étaient pas présents. Le protocole prévoyait spécifiquement 16 étapes d’exécution gratuites pour permettre aux contrats de rejeter les transactions qui ne contenaient pas ces frais.
À ce stade, le protocole Ethereum était entièrement ma création. À partir de ce moment, de nouveaux participants rejoignirent le projet. Le plus important, de très loin, fut Gavin Wood, qui me contacta par un message sur about.me en décembre 2013:
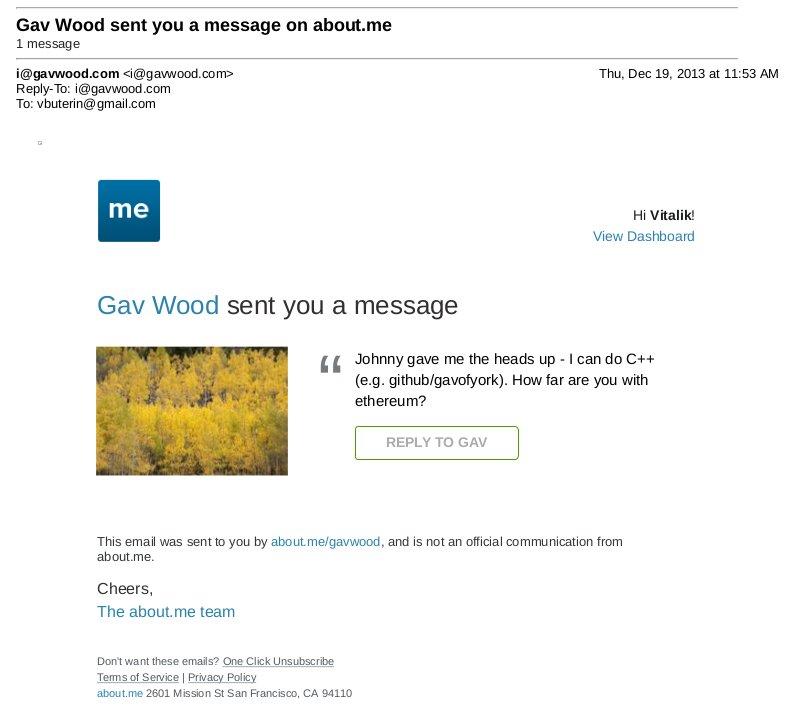
Jeffrey Wilcke, développeur principal du client Go (alors appelé “ethereal”) me conctacta également et commença à coder à peu près au même moment, même si ses contributions se concentraient sur le développement du client plutôt que sur la recherche autour du protocole.
« Salut Jeremy, ravi d’apprendre que tu t’intéresses à Ethereum… »
Les contributions initiales de Gavin étaient de deux ordres. D’une part, vous avez peut être remarqué que le modèle d’appels des contrats dans l’idée initiale était asynchrone : même si le contrat A pouvait créer une « transaction interne » au contrat B (« transactions internes » est un terme inventé par Etherscan, a l’origine elles étaient juste appelées « transactions », puis « appels de messages » (message calls) ou « appels »), l’exécution de ladite transaction interne ne démarrait pas tant que l’exécution de la première transaction n’était pas complètement terminée. Par conséquent, il était impossible d’utiliser ces transactions internes pour récupérer une information depuis d’autres contrats ; la seule façon de le faire était en utilisant l’opcode EXTRO (un peu comme un SLOAD qu’on pourrait utiliser pour lire le stockage d’autres contrats), et cette dernière méthode a été supprimée par la suite grâce à Gavin entre autres.
Lorsqu’il a mis en œuvre mes spécifications initiales, Gavin a naturellement choisi d’implémenter les transactions internes sur un mode synchrone, sans même réaliser que l’intention était différente ; autrement dit, dans la mise en œuvre de Gavin, la transaction interne était exécutée immédiatement, et lorsque cette exécution était finalisée, la machine virtuelle reprenait l’exécution du contrat initial à l’opcode suivant. Cette approche nous a semblé à tous les deux supérieure et est donc devenue partie intégrante des spécifications.
D’autre part, une discussion entre lui et moi (pendant une balade à San Francisco, dont les détails sont par conséquents perdus à jamais dans les vents de l’histoire, avec peut être une copie ou deux dans les archives de la NSA) a conduit à restructurer le modèle de frais de transactions, en s’éloignant de l’approche « contrat payeur » pour aller vers une approche « envoyeur payeur ». Dans le même temps, nous avons pivoté vers l’architecture « gas » d’aujourd’hui. Plutôt que chaque transaction individuelle s’exécute immédiatement en consommant une partie des ether, l’envoyeur de la transaction paye pour son exécution et se voit allouer du « gas » (grosso modo, un compteur d’étapes de calcul), les étapes de calcul piochant dans ce gas alloué. Si la transaction est à court de gas, le gas est perdu mais l’exécution de la transaction est entièrement annulée ; ce qui semblait la solution la plus sûre puisque cela faisait disparaître toute la problématique des attaques liées à l’exécution partielle des contrats qui nous posait de nombreux problèmes. Une fois l’exécution de la transaction arrivée à son terme, les frais correspondant au gas non consommé sont remboursés.
Il faut également attribuer à Gavin une évolution progressive, depuis la vision initiale d’Ethereum en tant que plateforme de création de monnaie programmable avec des contrats basés sur la blockchain pouvant détenir des actifs et les transférer sur la base de règles prédéfinies, vers une plateforme de calcul à usage générique. Cela a commencé avec de subtils changements en terme d’emphase et de terminologie, puis l’influence est devenue plus forte avec la mise en avant du « Web3 » qui voyait Ethereum comme l’une des pièces d’un ensemble de technologies décentralisées, les deux autres étant Whisper et Swarm.
D’autres changements sont arrivés en 2014, suggérés par d’autres contributeurs. Nous en sommes finalement revenus à une architecture à piles (stack-based) selon une suggestion d’Andrew Miller, entre autres.
Charles Hoskinson suggéra un changement depuis le SHA256 de Bitcoin vers le plus récent SHA3 (ou, plus précisément keccak256). Après un long débat, des discussions avec Gavin, Andrew et d’autres permirent de conclure que la taille des valeurs devait être limitée à 32 octets ; l’autre option, des entiers de taille illimitée, rendait trop complexe le calcul du gas requis pour une addition, une multiplication ou une autre opération.
L’algorithme de minage que nous avions initialement en tête, en Janvier 2014, était un système appelé Dagger :
https://github.com/ethereum/wiki/blob/master/Dagger.md
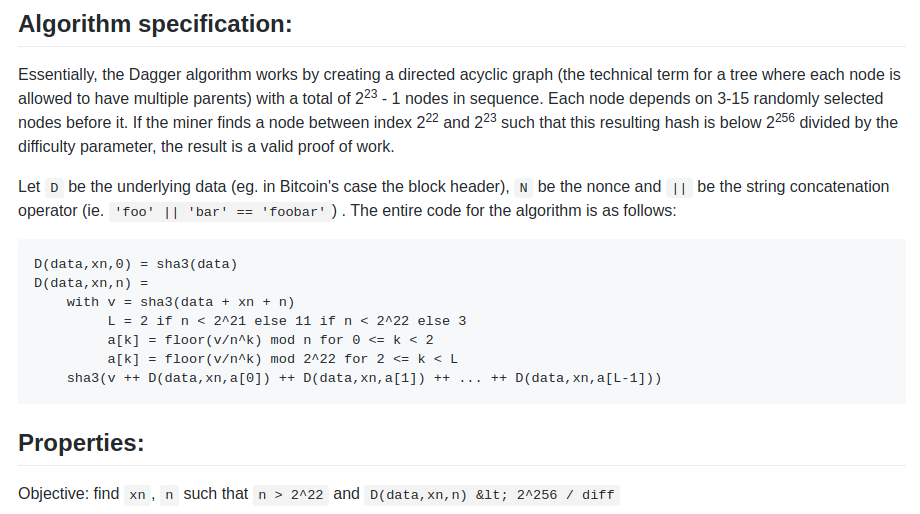
Le nom de Dagger provient du « directed acyclic graph » (DAG) ou graphe orienté acyclique, la structure mathématique utilisée dans l’algorithme. L’idée était qu’à chaque bloc N, un nouveau DAG serait généré pseudo-aléatoirement depuis une graine (seed), et que la couche inférieure du DAG serait une collection de nœuds qui prendrait plusieurs gigaoctets à stocker. Cependant, la génération d’une valeur individuelle dans le DAG ne requiert le calcul que de quelques milliers d’entrées. Un « calcul Dagger » impliquait de générer un certain nombre de valeurs dans des positions aléatoires de cette couche inférieure pour les hasher ensemble. Cela signifiait qu’il y avait une façon rapide de réaliser un calcul Dagger – avoir préchargé les données en mémoire – et une façon lente, mais peu gourmande en mémoire – regénérer chaque valeur depuis le DAG qu’il faut reprendre de zéro.
L’idée derrière cet algorithme était d’avoir la même « résistance mémoire » (memory hardness) que d’autres algorithmes courants à ce moment-là, comme Scrypt, mais tout en permettant la création de clients légers (light clients). Les mineurs utiliseraient la méthode rapide, et leur minage serait donc contraint par la bande passante de leur mémoire (la théorie étant que la RAM grand public est déjà très fortement optimisée et qu’il serait difficile de l’optimiser davantage avec des ASIC), mais les clients légers pourraient utiliser la méthode de vérification sans mémoire mais plus lente. La méthode rapide se compte en microsecondes et la méthode sans mémoire en millisecondes, ce qui reste tout à fait viable pour un client léger.
De ce point de départ, l’algorithme devait changer de nombreuses fois pendant le développement d’Ethereum. L’idée suivante était la « preuve de travail adaptive » (adaptive proof of work) ; ici la preuve de travail impliquait d’exécuter des contrats Ethereum sélectionnés aléatoirement. Nous avions de bonnes raisons de croire que cela rendait l’algorithme davantage résistant aux ASICs. Si un ASIC était développé, des mineurs concurrents auraient tout intérêt à déployer des contrats que cet ASIC ne saurait pas exécuter efficacement. Comme il n’existe pas d’ASIC pour les calculs génériques – cela s’appelle un CPU – il était simplement possible de mettre en place ces mécanismes d’incitations antagonistes pour créer une preuve de travail qui était en pratique une exécution de calculs génériques.
Cette idée a été abandonnée pour une simple raison : les attaques à longue portée (long-range attacks). Un attaquant pouvait commencer une chaîne depuis le bloc 1, la remplir avec uniquement des contrats simples pour lesquels il pouvait créer un matériel spécialisé, et rapidement dépasser la chaîne principale. Donc… retour à la case départ.
L’algorithme suivant était appelé Random Circuit, décrit dans ce document, proposé par Vlad Zamfir et moi-même et analysé par Matthew Wampler-Doty et d’autres. L’idée était également de simuler des calculs génériques dans un algorithme de minage, mais cette fois en exécutant des circuits générés automatiquement. Il n’existait aucune preuve que quelque chose basé sur ces principes ne pourrait pas fonctionner mais les experts en matériel informatique contactés en 2014 avaient des avis assez pessimistes à ce sujet. Matthew Wampler-Doty lui-même suggéra une preuve de travail basée sur la résolution de problèmes SAT mais cette idée fut également rejetée en fin de compte.
Enfin, nous sommes presque revenus au point de départ avec un algorithme appelé « Dagger Hashimoto ». « Dashimoto », comme il était parfois abrégé, a beaucoup emprunté à Hashimoto, un algorithme de preuve de travail conçu par Thaddeus Dryja qui a exploré en premier la notion de « preuve de travail liée aux entrées / sorties » (I/O bound proof of work), dans laquelle le facteur limitant principal de la vitesse de minage n’est pas le nombre de hashs par secondes mais plutôt le nombre de mégaoctets par seconde d’accès RAM. Cependant, nous avons combiné cette idée avec la notion d’ensembles de données générées par DAG compatibles avec les clients légers qu’apportait Dagger. Après de nombreuses séances de peaufinage par Matthew, Tim, moi-même et d’autres, les idées ont finalement convergé vers un algorithme que nous appelons dorénavant Ethash.
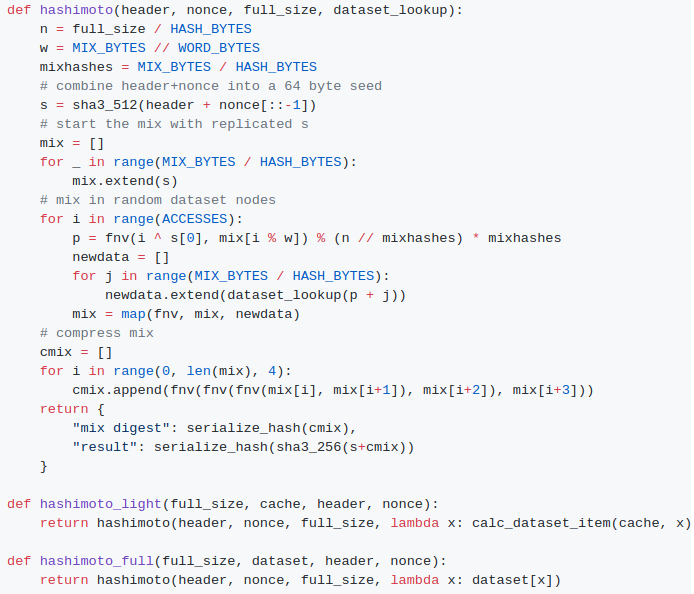
A l’été 2014, le protocole était globalement stabilisé, à l’exception significative de l’algorithme de preuve de travail qui ne devait pas atteindre sa phase « Ethash » avant le début de 2015, même si une spécification semi-formelle existait sous la forme du « Livre Jaune » (yellow paper) de Gavin.

En août 2014, je développais le concept d’oncle (uncle), permettant à la blockchain Ethereum d’avoir un temps de bloc plus court et une meilleure capacité générale en réduisant les risques de centralisation, formellement introduit dans le PoC6.
Des discussions avec l’équipe de Bitshares nous ont conduit à évaluer la pertinence d’ajouter des « tas » (heaps) comme structure de données principale mais nous avons finalement abandonné cette idée par manque de temps, et des audits de sécurité puis des attaques par DoS ont ensuite montré que ces structures sont bien plus difficiles à mettre en œuvre de façon sécurisée que nous ne le pensions à l’époque.
En septembre, Gavin et moi planifièrent les deux prochains changements majeurs dans la conception du protocole.
En premier lieu, en plus de l’arbre de l’état (state tree) et et de l’arbre des transactions (transaction tree), chaque bloc contiendrait également un arbre des reçus (receipt tree). L’arbre des reçus inclurait les hashs des logs créés par une transaction, ainsi que les racines d’états intermédiaires. Les logs permettent aux transactions de créer des « sorties » qui sont sauvegardées dans la blockchain, et sont accessibles pour les clients légers mais pas pris en compte pour le calcul des états futurs. Les applications décentralisées peuvent ainsi faire des requêtes relatives à des événements comme des transferts de tokens, des achats, des ordres créés et remplis, des débuts d’enchères, et ainsi de suite. D’autres idées avaient été explorées, comme la création d’un arbre de Merkle à partir de la trace de l’exécution complète des transactions pour pouvoir les prouver ; les logs ont été choisis car ils présentaient un compromis acceptable entre perfection et simplicité.
Le second changement concernait les fonctions précompilées (precompiles), qui résolvaient la problématique de permettre l’utilisation des fonctions cryptographiques complexes sans surcharger l’EVM. Nous avons également exploré beaucoup d’autres idées plus ambitieuses sur les « contrats natifs » (native contracts), où lorsque les mineurs mettaient en œuvre une version optimisée de certains contrats ils pouvaient « voter » pour que le prix de ces contrats spécifiques soit réduit, donc les contrats que les mineurs pouvaient exécuter plus rapidement auraient eu naturellement un prix en gas moins élevé ; cependant nous avons rejeté ces idées car elles ne laissaient pas entrevoir une façon crypto-économiquement sûre de les mettre en œuvre. Un attaquant pouvait toujours créer un contrat exécutant une version faussée d’une opération cryptographique, distribuer cette version faussée à eux-mêmes et leurs amis pour leur permettre d’exécuter ce contrat beaucoup plus vite, puis de voter un prix en gas minimum avant de l’utiliser pour attaquer le réseau par DoS (déni de service). Nous sommes donc parti sur une approche beaucoup moins ambitieuse qui consistait à définir un petit nombre de fonctions pré-compilées dans le protocole pour des opérations communes comme les hashs et les mécanismes de signature.
Gavin fut également une des premières voix importantes en faveur de l’idée d’« abstraction du protocole » (protocol abstraction) : il s’agissait de déplacer le plus possible d’éléments du protocole comme les soldes en ether, les algorithmes de signature de transaction, les nonces, etc. dans des contrats, dans le but théorique d’atteindre la situation où tout le protocole ethereum pouvait être décrit comme un appel de fonction dans une machine virtuelle se trouvant dans un état pré-initialisé. Nous n’avions pas assez de temps pour implémenter ces idées dans la première version d’Ethereum (Frontier). Mais ces principes doivent être progressivement intégrés par les modifications apportées par Constantinople, le contrat Casper et la spécification du sharding.
Tout ceci fut mis en oeuvre dans le PoC7 ; après celui-ci, le protocole n’a pas vraiment changé, à l’exception de détails le plus souvent (mais pas toujours) mineurs révélés par les audits de sécurité…
Début 2015, les audits de sécurité de pré-lancement organisés par Jutta Steiner et d’autres inclurent tant des audits de code informatique que des audits académiques. Les audits de code furent principalement réalisés sur les implémentations en C++ et en Go, menés respectivement par Gavin Wood et Jeffrey Wilcke, même si il y eut également un audit de plus faible envergure sur l’implémentation pyethereum. Les deux audits académiques furent réalisés par Itaay Eyal (bien connu pour l’idée du « minage égoïste » (selfish mining) et par Andrew Miller et d’autres de Least Authority. L’audit d’Eyal conduisit à un changement mineur dans le protocole : la difficulté totale de la chaîne n’inclurait pas les oncles. L’audit de Least Authority était davantage tourné vers les smart contracts et les principes économiques du gas, ainsi que l’arbre Patricia. Cet audit engendra plusieurs changements dans le protocole, dont l’utilisation de sha3(addr) et sha(key) comme clés de trie au lieu d’employer directement les adresses et les clés ; cela rend plus difficile une attaque sur le trie.

Et un avertissement qui était peut-être un peu en avance sur son temps…
Un autre aspect significatif remis en cause fut le mécanisme du vote sur la limite en gas par bloc. À ce moment, nous étions déjà inquiets du manque de progrès réalisé dans le débat sur la taille des blocs dans l’écosystème bitcoin et nous voulions un fonctionnement plus souple pour Ethereum qui pourrait s’ajuster avec le temps lorsque nécessaire. Mais le challenge était de déterminer la limite optimale. Mon idée initiale était de mettre en œuvre une limite dynamique, avec pour stratégie de vote par défaut 1,5 fois la moyenne mobile exponentielle de l’utilisation réelle du gas, pour qu’à long terme en moyenne les blocs soient pleins à 2/3. Cependant Andrew montra que ce fonctionnement était exploitable de plusieurs façons : par exemple, les mineurs qui voudraient augmenter la limite n’auraient qu’à inclure dans leurs blocs des transactions qui consomment un très gros montant de gas mais prennent très peu de temps à être traités, et donc créer des blocs pleins sans coût particulier pour eux. Le modèle de sécurité était donc, au moins dans le sens de l’augmentation, d’avoir simplement un vote des mineurs sur la limite de gas.
Nous ne sommes pas arrivés à concevoir une stratégie de limite de gas moins susceptible de défaillir et la recommandation d’Andrew fut simplement de faire voter explicitement les mineurs sur la limite de gas, avec la stratégie par défaut fixée selon la règle des 1,5x de la moyenne mobile exponentielle. Le raisonnement était que nous étions encore très loin de connaître la bonne approche pour définir la limite de gas maximum, et le risque qu’une approche échoue semblait plus importante que celle de voir les mineurs abuser de leur pouvoir de vote. Par conséquent, il valait mieux laisser les mineurs voter sur la limite de gas et accepter le risque que cette limite aille trop haut ou trop bas, en bénéficiant de la souplesse et de la possibilité pour les mineurs de collaborer pour réduire ou augmenter la limite de gas rapidement si nécessaire.

Après un mini-hackathon entre Gavin, Jeff et moi, le PoC9 était lancé en mars et devait être la dernière version en preuve de concept. Un réseau de test, Olympic, fonctionna pendant quatre mois en utilisant le protocole prévu pour le réseau principal. Le plan à long terme pour Ethereum fut alors établi. Vinay Gupta écrivit à cette époque un article de blog appelé « Le processus de lancement d’Ethereum » (The Ethereum Launch Process) décrivant les quatre étapes prévues pour le lancement d’Ethereum : Frontier, Homestead, Metropolis et Serenity.
Olympic tourna pendant quatre mois. Pendant les deux premiers mois, de nombreux bugs furent trouvés dans les implémentations existantes, des échecs de consensus se produisirent entre autres soucis et, finalement, vers juin, le réseau s’était stabilisé de façon notable. En juillet la décision était prise de geler le code existant et de réaliser le lancement, qui intervint le 30 juillet.
