1.X Files : Introduction à la spécification des signatures témoins
Interview


Article de Griffin Ichiba Hotchkiss sur blog.ethereum.org, traduit par Jean Zundel
Les articles précédents traitaient de Stateless Ethereum en général, en faisant le point sur la recherche et en balayant tous les sujets concernés. Celui-ci se concentre sur la manière dont la spécification du sans-état est rédigée. On y aborde notamment la structure d’un witness, la notation formelle des règles de grammaire et le comportement de certains bisons de l’état de New York.

Comme beaucoup d’entre nous ont un peu de temps libre, j’ai pensé que c’était l’occasion de passer à quelque chose d’autre ; un peu aride, peut-être, mais fondamental pour le projet Stateless Ethereum. Il s’agit de comprendre la spécification formelle des signatures témoins.
Tout comme le Battlecruiser de StarCraft, on va commencer en douceur. La spécification des signatures n’est pas un concept particulièrement compliqué, mais il est profond. Cette profondeur peut paraître impressionnante mais l’exploration en vaut la peine, car elle fournira des notions qui, pour votre plus grand plaisir de nerd, s’étendent bien au-delà du monde de la blockchain ou même de l’informatique !
À la fin de cette introduction, vous devriez au moins avoir acquis assez de confiance en vous pour comprendre en quoi consiste la spécification des signatures témoins dans Stateless Ethereum. J’essaierai aussi de ne pas rester trop sérieux tout le temps.
Récapitulons : ce que vous devez savoir sur l’état
Stateless Ethereum est bien entendu un terme un peu inapproprié, car l’objet de cette initiative est en fait l’état, et plus particulièrement le moyen de rendre optionnel le fait de conserver cet état. Si vous n’avez pas suivi cette série, vous pourrez trouver profitable de jeter un œil sur mon introduction à l’état de Stateless Ethereum. En voici cependant un bref résumé. Vous pouvez le sauter si vous pensez suffisamment maîtriser ce sujet.
Ce que l’on appelle « état » complet d’Ethereum décrit le statut actuel de tous les comptes et de tous les soldes, ainsi que la mémoire collective de tous les contrats autonomes déployés dans l’EVM. Tout bloc finalisé dans la blockchain ne possède qu’un seul état, lequel est accepté par tous les participants du réseau. Cet état est modifié à chaque nouveau bloc ajouté à la chaîne.
L’état d’Ethereum est représenté in silico par un trie de Merkle-Patricia : une structure de hashes, d’empreintes cryptographiques de données, qui organise toutes les informations (comme le solde d’un compte) en une unité massivement connectée dont l’unicité peut être vérifiée. Le trie d’état complet est trop énorme pour être visualisé, mais il en existe une « version jouet » qui nous sera utile quand nous en arriverons aux signatures témoins :
Comme des chenilles cryptographiques magiques, les comptes et le code des contrats vivent dans les feuilles et les branches de cet arbre qui, par des opérations successives de hachage, mènent à une empreinte de racine unique. Quand vous voulez savoir si deux copies d’un trie d’état sont les mêmes, il suffit de comparer les empreintes des racines. La maintenance d’un consensus relativement sûr et indiscutable concernant un état « canonique » constitue l’essence de ce que fait une blockchain.
Pour soumettre une transaction à inclure dans le bloc suivant, ou pour valider qu’un changement est cohérent avec le dernier bloc inclus, les nœuds Ethereum doivent conserver une copie complète de l’état et recalculer l’empreinte cryptographique racine (encore et toujours). Stateless Ethereum est un ensemble de changements destinés à éliminer cette exigence en ajoutant ce que l’on appelle un witness, une signature témoin.
Schéma d’une signature
Avant de plonger dans la spécification, il sera utile de présenter la notion de signature témoin. Encore une fois, une explication plus détaillée se trouve dans l’article sur l’état d’Ethereum dont le lien se trouve plus haut.
Une signature ressemble un peu à une antisèche pour un étudiant (client) négligent (sans état). Elle ne contient que l’information minimale nécessaire pour passer l’examen (soumettre un changement d’état valide à inclure dans le bloc suivant). Au lieu de lire tout le livre de cours (conserver une copie de l’état courant), l’étudiant négligent (le client sans état) demande à un ami (un nœud complet) une antisèche pour donner sa réponse.
En termes très abstraits, une signature fournit toutes les empreintes cryptographiques d’un trie d’état, combiné avec des informations « structurelles » sur l’emplacement de ces empreintes dans le trie. Cela permet à un nœud « négligent » d’inclure de nouvelles transactions dans son état et de calculer une nouvelle empreinte racine localement, sans avoir besoin de télécharger une copie complète du trie d’état.
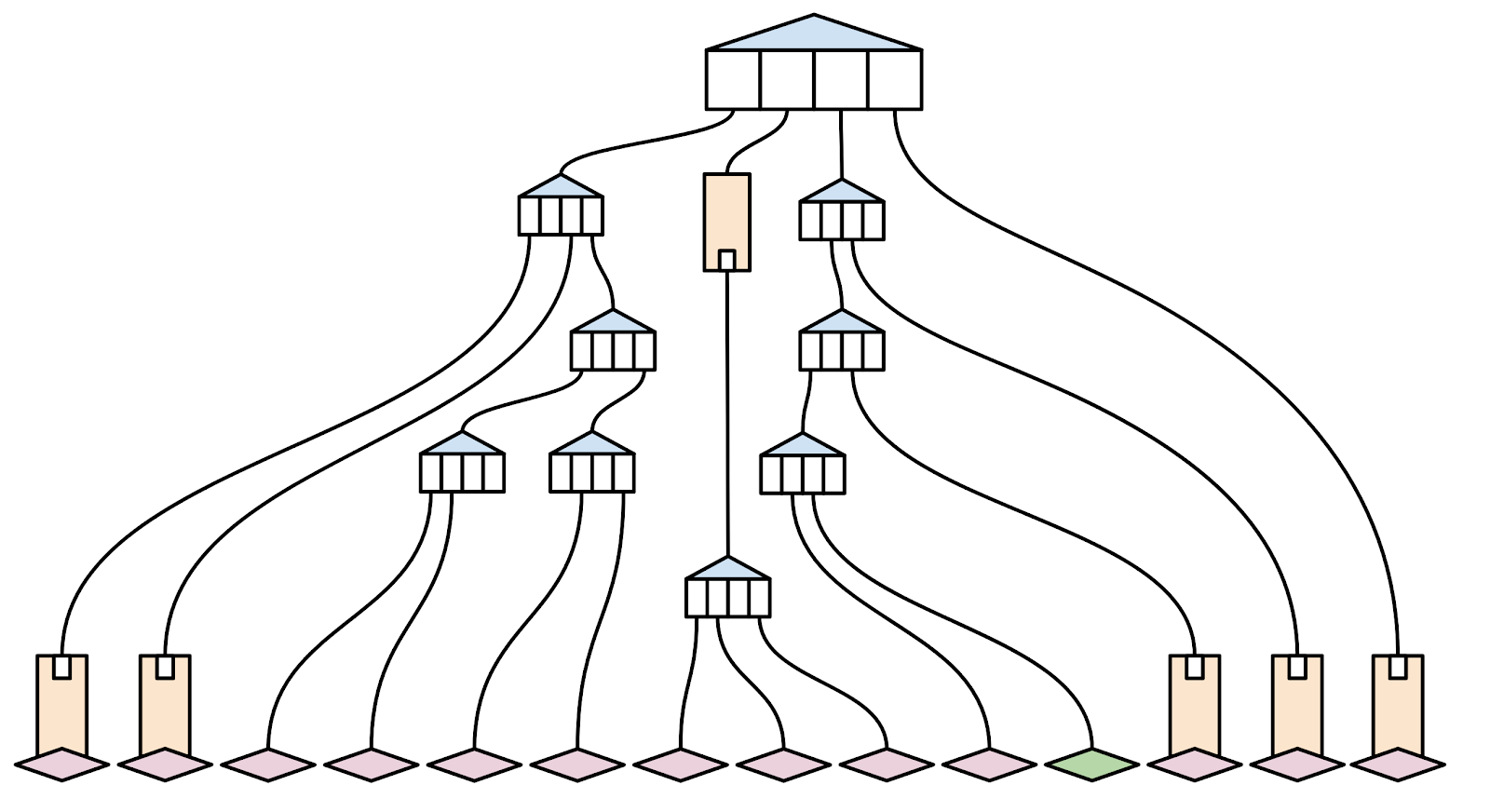
Mettons de côté cette idée caricaturale et passons à une représentation plus concrète. Voici la « vraie » visualisation d’un témoin :
Je recommande d’ouvrir cette image dans un nouvel onglet afin de pouvoir zoomer pour mieux l’apprécier. Ce témoin a été sélectionné parce qu’il est relativement petit et qu’il est facile d’en dégager des détails. Chaque petit carré dans cette image représente un simple nibble, ou la moitié d’un octet, et vous pouvez le vérifier par vous-même en comptant le nombre de carrés qu’il vous faut « traverser » en commençant par la racine pour arriver à un solde en ether (vous devriez obtenir 64). Puisque nous en sommes à cette image, observez le gros bout de code dans l’une des transactions qui doit être inclus pour un appel de contrat ; le code prend une part non négligeable de la signature et pourrait être réduit par merklisation de code (que nous explorerons un autre jour).
Quelques formalités
L’une des principales caractéristiques d’Ethereum en tant que protocole est son indépendance vis à vis d’une implémentation donnée. C’est pourquoi, au lieu d’un seul client officiel comme nous le voyons avec Bitcoin, il existe plusieurs versions complètement différentes de clients Ethereum. Ces clients, écrits dans différents langages de programmation, doivent adhérer au Ethereum Yellow Paper qui exprime en termes formels comment un client doit se comporter pour participer au protocole Ethereum. Le développeur d’un client Ethereum n’a donc pas à se préoccuper de possibles ambiguïtés dans le système.
La Witness Specification a le même but : fournir une description sans ambiguïté de ce qu’est une signature témoin pour faciliter son implémentation dans n’importe quel langage pour n’importe quel client. Si Stateless Ethereum devient une réalité, la spécification des signatures pourra être insérée en annexe dans le Yellow Paper.
La signification de « sans ambiguïté » dans ce contexte est plus stricte que ce que l’on entend par là dans un discours ordinaire. Ce n’est pas tant que la spécification formelle est une description vraiment, mais vraiment, mais alors vraiment détaillée d’une signature et de son comportement. Cela signifie que, idéalement, il existe littéralement une et une seule manière de décrire une signature donnée. Si l’on adhère à la spécification formelle, il devient impossible d’écrire une implémentation de Stateless Ethereum qui génère des signatures différentes d’une autre implémentation se conformant aux mêmes règles. C’est essentiel car la signature va (espérons-le) devenir un nouveau pilier du protocole Ethereum ; elle doit être correcte par construction.
Une question de sémantique (et de syntaxe)
Bien que le « développement blockchain » implique généralement quelque chose de nouveau et d’excitant, il faut bien dire que l’essentiel en provient de traditions bien plus anciennes et matures en informatique, en cryptographie et en logique formelle. Tout ceci apparaît dans la spécification des signatures ! Afin de comprendre comment cela fonctionne, nous devons nous familiariser avec certains termes techniques, et à cet effet nous allons faire un petit détour par la linguistique et la théorie des langages formels.
Lisez à haute voix les deux phrases suivantes, et faites très attention à votre intonation et à la cadence :
- vertes furieusement idées d’incolores dorment
- d’incolores idées vertes dorment furieusement
Je parie que votre diction pour la première phrase était un peu robotique, avec une accentuation plate et une pause après chaque mot. En revanche, la seconde a semblé naturelle bien qu’un peu loufoque. Même si elle ne veut rien dire, la seconde phrase possède un sens que la première n’a pas. Il s’agit ici de vous diriger intuitivement vers la distinction entre syntaxe et sémantique. Si vous parlez français, vous comprenez ce que représentent les mots (leur contenu sémantique) mais cela n’a aucune importance ici ; vous avez remarqué une différence entre une grammaire valide et une grammaire invalide (leur syntaxe).
Cette phrase en exemple provient d’un article de 1956 par un certain Noam Chomsky, dont le nom peut vous dire quelque chose. Bien qu’il soit maintenant connu comme un influent penseur politique et social, ses premières contributions académiques furent dans le domaine de la logique et de la linguistique et, dans cet article, il a créé l’un des systèmes les plus utiles de classification des langages formels.
Chomsky se consacrait à la description mathématique de la grammaire, à la manière dont on peut catégoriser les langages d’après leurs règles grammaticales, et aux propriétés de ces catégories. L’une des propriétés qui nous intéresse ici est l’ambiguïté syntaxique.
Ambiguïté du buffalo
Considérons la phrase anglaise suivante, qui est grammaticalement correcte : « Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo. » C’est un exemple classique qui illustre à quel point la syntaxe anglaise peut être ambiguë. Si vous comprenez que, selon le contexte, le mot « buffalo » peut être utilisé comme un verbe (intimider), un adjectif (de Buffalo, NY) ou un nom (bison) qui peut être invariable en anglais, vous pouvez analyser la phrase selon l’appartenance de chaque mot.
Nous pouvons aussi employer des mots complètement différents, en plusieurs phrases. « Vous connaissez ces bisons de l’état de New York que d’autres bisons de l’état de New York intimident ? Eux-mêmes intimident. Plus précisément, ils intimident des bisons de l’état de New York ». Ou, plus simplement, « Les bisons de Buffalo que des bisons de Buffalo intimident intimident des bisons de Buffalo ».
Et si nous voulons retirer cette ambiguïté, tout en nous restreignant au seul emploi du mot « buffalo », dans une seule phrase ? C’est possible mais nous devons un peu modifier les règles de l’anglais. Notre nouveau « langage » deviendra un peu plus exact. Une façon possible de faire serait de marquer chaque mot pour indiquer son rôle dans la phrase, comme ceci :
Buffalo{pn} buffalo{n} Buffalo{pn} buffalo{n} buffalo{v} buffalo{v} Buffalo{pn} buffalo{n}
Tout ceci reste peut-être encore obscur pour le lecteur. Pour que ce soit encore plus exact, essayons une petite substitution pour nous aider à regrouper quelques-uns de ces « buffalo » en troupeau. Tout bison de Buffalo, NY n’est qu’une version particulière de ce qu’on appelle un groupe nominal ou noun phrase, <NP>. Nous pouvons substituer <NP> dans la phrase à chaque fois que nous rencontrons la chaîne Buffalo{pn} buffalo{n}. Comme nous devenons un peu plus formels, utilisons une notation plus brève pour cette règle de substitution et celles à venir en écrivant :
<NP> ::= Buffalo{pn} buffalo{n}
où ::= signifie « Ce qui est à gauche peut être remplacé par ce qui est à droite ». Attention, cette relation ne doit pas fonctionner dans l’autre sens ; imaginez l’état dans lequel se mettrait le bison de Boulder !
En appliquant notre règle de substitution à toute la phrase, elle devient :
<NP> <NP> buffalo{v} buffalo{v} <NP>
Cela dit, la confusion persiste néanmoins, car cette phrase contient une proposition relative implicite, qui peut être explicitée en insérant le pronom « that » (qui) dans la première partie de notre phrase, c’est-à-dire <NP> *that* <NP> buffalo{v}…
Donc créons une règle de substitution qui regroupe la proposition relative (relative clause) en <RC>, et écrivons :
<RC> ::= <NP> buffalo{v}
De plus, comme une proposition relative ne fait que clarifier un groupe nominal, les deux pris ensemble sont équivalents à un autre groupe nominal :
<NP> ::= <NP><RC>
Ces règles étant établies et appliquées, nous pouvons écrire la phrase :
<NP> buffalo{v} <NP>
Cela commence à ressembler à quelque chose, et on parvient ainsi au cœur de la relation exprimée par cette phrase : un groupe donné de bisons intimide un autre groupe de bisons.
Au point où nous en sommes, pourquoi ne pas aller jusqu’au bout ? Chaque fois que « buffalo » en tant que verbe précède un nom, nous pourrions appeler cela un groupe verbal (verb phrase) ou <VP>, et définir une règle :
<VP> ::= buffalo{v}<NP>
Cela fait, nous avons notre phrase unique, complète et valide, que nous pouvons appeler S :
S ::= <NP><VP>
Ce que nous avons fait ici peut être représenté visuellement :

Cette structure semble étrangement familière, n’est-ce pas ?
L’exemple du Buffalo est un peu idiot et pas très rigoureux, mais il suffit pour montrer à quoi ressemble l’étrange langage mathématique de la spécification des signatures témoins, que j’ai sournoisement introduit dans l’exposé sur les bisons. Elle s’appelle la forme de Backus-Naur, et elle est souvent employée dans des spécifications formelles telles que celle-ci pour de nombreux scénarios du monde réel.
Les « règles de substitution » que nous avons définies pour notre sous-ensemble de langue anglaise nous ont permis de nous assurer que, étant donné un troupeau de « buffalo », nous pouvions construire une phrase anglaise « valide » sans connaître la signification du mot buffalo dans le monde réel. Dans la première classification déterminée par Chomsky, un langage possédant des règles de grammaire suffisamment exactes pour arriver à ce résultat est appelé un langage non-contextuel.
Le plus important est que cette règle assure que pour chaque phrase comprenant le(s) mot(s) buffalo{np|n|v}, il existe une et une seul manière de construire la structure de données illustrée dans le diagramme de l’arborescence ci-dessus. Désambiguïsation !
Allez, et lisez la spec
Un witness n’est finalement qu’un grand objet encodé dans un tableau d’octets. Du point de vue (anthropomorphique) d’un client sans état, ce tableau d’octets ressemble un peu à une longue phrase composée de mots très similaires. Tant que tous les clients suivent le même ensemble de règles, le tableau d’octets ne peut se convertir qu’en une et une seul structure de données, quelle que soit la façon dont l’implémentation choisit de la représenter en mémoire ou sur disque.
Les règles de production, rédigées en section 3.2, sont un peu plus complexes et beaucoup moins intuitives que celles que nous avons employées dans notre petit exemple, mais l’esprit reste le même : exprimer des lignes directrices sans ambiguïté pour un client sans état (ou un développeur écrivant un client), lignes directrices à suivre pour être certain d’arriver à un résultat correct.
J’ai volontairement omis de nombreuses choses dans cet exposé et le labyrinthe des langages formels va évidemment bien plus loin. Je voulais simplement fournir une introduction suffisante pour dépasser ce premier obstacle à la compréhension. Maintenant, il est temps de passer à Wikipedia et de vous attaquer au reste par vous-même !
Comme toujours, si vous avez des retours, des questions ou des requêtes de nouveaux sujets, vous pouvez joindre @gichiba ou @JHancock sur Twitter.
Commentaires